TCP 队头拥塞 和 HTTP 队头拥塞 和 QUIC
在看的 QUIC 资料中提到了一点:「QUIC 解决了 H2 存在的队头拥塞问题」,我的第一反应是,之前 H2 没有解决队头拥塞问题吗?查一下才知道 TCP 队头拥塞 和 HTTP 队头拥塞原来是不一样的队头拥塞。
HTTP 1.1 Pipeline
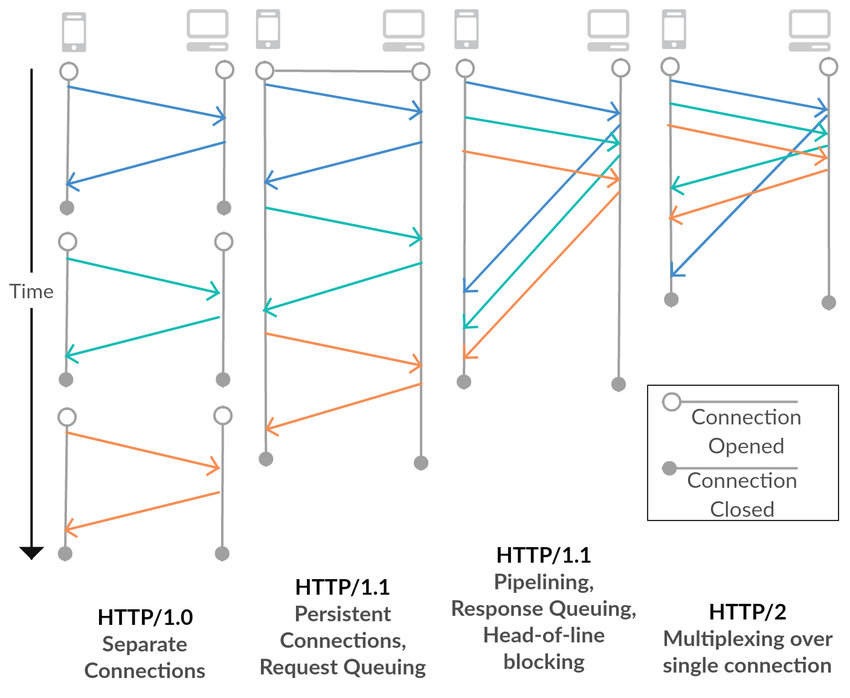
HTTP 1 存在的请求低效问题的原因是只能单路连接,每个 TCP 连接只能对应一个 HTTP 请求,每个 HTTP 请求只请求一个资源,发送方只能通过建立多个 TCP 连接来解决(图中第一列)。
HTTP 1.1 Pipeline 用于改善这一瓶颈,允许在 keep-alive 的基础上可选地使用 Pipeline。 同一个 TCP 连接中,在上一个请求的响应还没有收到时就发送后续的请求,也就是将多条请求放入队列中顺序发送,在髙时延网络条件下,这样可以有效降低 RTT,提高性能(图中第三列)。
Keep-alive 和 Pipeline 的区别:
Keep-alive 表示保持 TCP 连接,不立即关闭,这样一个 TCP 连接可以发送多个 HTTP 请求(图中第二列)
Pipeline 表示在同一个 TCP 连接中,之前的 HTTP Response 还没收到就可以发送后续的 request
Pipeline 必须在 Keep-alive 开启的情况下才能使用
虽然得益于 Pipeline,request 的发送可以不需要再等待上一个 reponse 返回后再执行,但是这种技术在接收 response 时,要求必须按照发送 request 的顺序返回。
假如有 3 个请求,request2 和 request3 可以不等 response1 返回就发送,但是 response2 必须等待 response1 返回后再返回,同理,response3 必须等待 response2 返回后再返回。如果 request1 的处理比较耗时,迟迟没有返回 response1,那及即使 request2 和 request3 已经处理完毕,response2 和 response3 也不能返回,这就是 HTTP 层面的队头拥塞。
为什么必须保证顺序?因为 HTTP 的请求是没有序号的,利用的是 FIFO 来保证顺序,如果不严格限制返回顺序,response2 可能就会被错当做 request1 的返回结果。
HTTP2
HTTP2 将谷歌提出的 SPDY 协议进行了标准化,支持了数据流的多路复用、请求优先级以及 HTTP 报头压缩。
HTTP2 引入了「流」的概念,得以实现多路复用。
每个连接中可以包含多个流,而每个流中交错包含着来自两端的帧。也就是说同一个连接中是来自不同流的数据包混合在一起,如下图所示,每一块代表帧,而相同颜色块来自同一个流,每个流都有自己的 ID,在接收端会根据 ID 进行重装组合,就是通过这样一种方式来实现多路复用。
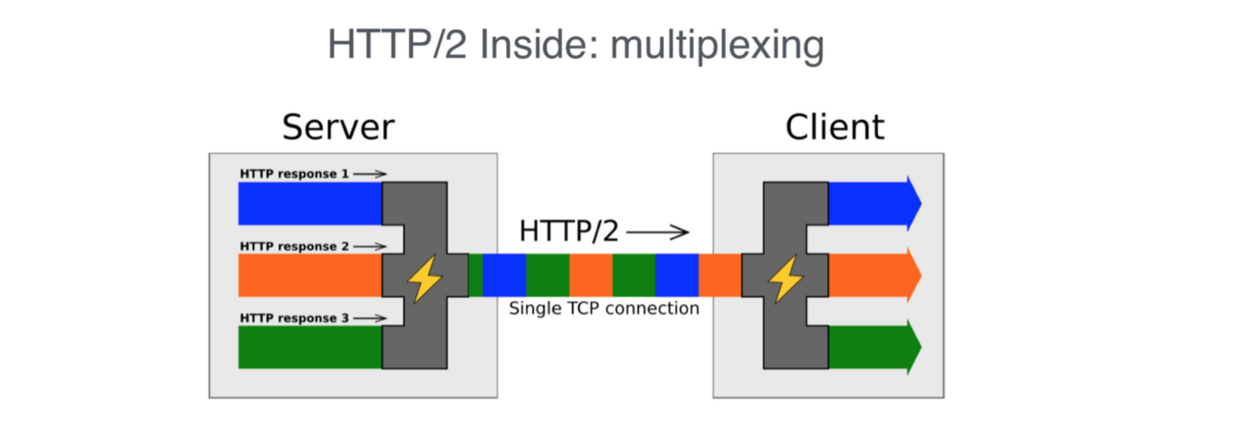
HTTP2 不用再受限于 HTTP1.1 pipeline 的 FIFO 操作,因为从机制上来说 HTTP2 中的请求是可以同时(并发)发送的,流 ID 也保证了 request 和 response 一一对应,因此 HTTP2 就解决了 HTTP 队头拥塞问题
TCP 队头拥塞
如果一个 TCP 报文丢失,后续报文将被接收端一直持有着,不交付给 HTTP,直到丢失的报文被发送端重传并到达接收端为止。这么做是为了保证应用层能够按照发送端的发送顺序接收数据。这就是 TCP 队头拥塞。
HTTP2 在 TCP 上层做了改造,但是实际上还是用的 TCP 连接,只要使用了 TCP,那 TCP 队头拥塞就没法避免,因为这是 TCP 本身的机制导致的。 所以说 HTTP2 只是解决了一部分的队头拥塞问题(HTTP 队头拥塞)
QUIC
QUIC 使用 UDP 协议的基础上实现了可靠传输,使用 QUIC 时,两端间仍然建立一个连接,该连接也经过协商使得数据得到安全且可靠的传输。当我们在这个连接上建立两个不同的数据流时,它们互相独立,也就是说,如果一个数据流丢包了,只有那个数据流必须停下来,等待重传。
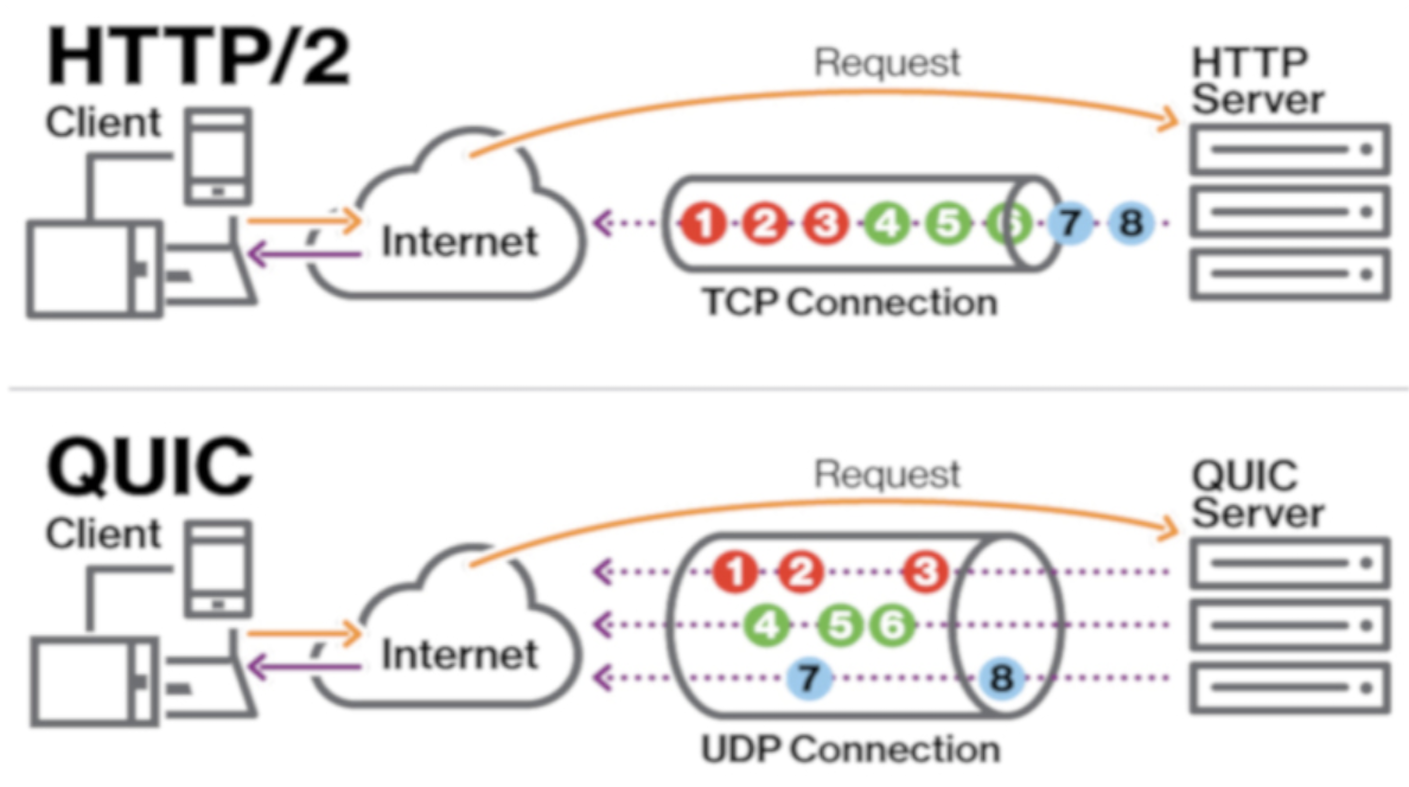
HTTP2 和 QUIC 的同时发送有点像并发和并行的关系,HTTP2 只是实现了逻辑上的并行。 看人 QUIC 直接不用 TCP 了,自然就不会有 TCP 队头拥塞问题。
总结
HTTP 队头拥塞:返回 HTTP response 的顺序必须和接收到 HTTP request 的顺序一致,前面的 request 没有接受完毕或者 response 没返回,后续 response 必须等待。
TCP 队头拥塞:TCP 必须按顺序将完整的数据交付给应用层,前面的 TCP 有报文丢失没法交付,后续的请求就必须等待。